출처:https://cheese10yun.github.io/spring-batch-basic/
스프링 부트 배치의 장점
- 대용량 데이터 처리에 최적화되어 고성능을 발휘한다.
- 효과적인 로깅,통계처리,트랜잭션 관리 등 재사용 가능한 필수 기능을 지원한다.
- 수동으로 처리하지 않도록 자동화되어 있다.
- 예외사항과 비정상 동작에 대한 방어 기능이 있다.
- 스프링 부트 배치는 반복적인 작업 프로세스를 이해하면 비즈니스로직에 집중할 수 있다.
스프링 부트 배치 주의사항
스프링 부트 배치는 스프링 배치를 간편하게 사용 할 수 있게 래핑한 프로젝트 입니다.
따라서 스프링 부트 배치와 스프링 배치에 모두에서 다음과 같은 주의사항을 염두해야 한다.
- 가능하면 단순화해서 복잡한 구조와 로직을 피해야한다.
- 데이터를 직접 사용하는 편이 빈번하게 일어나므로 데이터 무결성을 유지하는데 유효성 검사등의 방어책이 있어야 한다.
- 배치 처리 시스템 I/O 사용을 최소화 해야한다.잦은 I/O로 데이터베이스 커넥션과 네트워크 비용이 커지면 성능에 영향을 줄 수 있기 때문이다.따라서 가능하면 한번에 데이터를 조회하여 메모리에 저장해두고 처리를 한 다음,그 결과를 한번에 데이터베이스에 저장하는것이 좋다.일반적으로 같은 서비스에 사용되는 웹 API,배치,기타 프로젝트들을 서로 영향을 준다.따라서 배치 처리가 진행되는 동안 다른 프로젝트 요소에 영행을 주는 경우가 없는지 주의를 기울여야 한다.
- 스프링 부트는 배치 스케쥴러를 제공하지 않는다.따라서 배치 처리 기능만 제공하여 스케쥴링 기능은 스프링에서 제공하는 쿼치 프레임워크 등을 이용해야 한다.
- 리눅스 crontab 명령은 가장 간단히 사용할 수 있지만 이는 추천하지 않는다.crontab의 경우 각 서버마다 따로 스케쥴러를 관리해야 하며 무엇보다 크러스터링 기능이 제공되지 않는다.반면에 쿼츠같은 스케쥴링은 프레임워크를 사용한다면 크러스터링뿐만 아니라 다양한 스케쥴링 기능,실행 이력 관리등 여러 이점을 얻을 수 있다.
스프링 부트 배치 이해하기
배치의 일반적인 시나리오는 다음과 같은 3단계로 이루어진다.
읽기:데이터 저장소(일반적으로 데이터베이스)에서 특정 데이터 레코드를 읽는다.
처리:원하는 방식으로 데이터 가공/처리 한다.
쓰기:수정된 데이터를 다시 저장소(데이터베이스)에 저장한다.
배치 처리는 읽기->처리->쓰기 흐름을 갖는다.
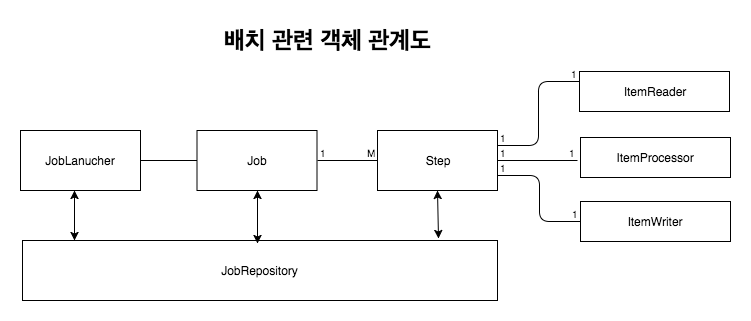
Job과 Step은 1:M
Step과 ItemReader,ItemProcessor,ItemWriter 1:1
Job이라는 하나의 큰 일감(Job)에 여러 단계(Step)을 두고,각 단계를 배치의 기본 흐름대로 구성한다.
Job
Job은 배치처리 과정을 하나의 단위로 만들어 표현한 객체이다.또한 전체 배치 처리에 있어 항상 최상단 계층에 있다.
위에서 하나의 Job(일감)안에는 여러 Step(단계)이 있다고 설명했던 바와 같이 스프링 배치에서 Job객체는 여러 Step 인스턴스를 포함하는 컨테이너 이다.
Job객체를 만드는 빌더는 여러 개가 있다.여러 빌더를 통합하여 처리하는 공장인 JobBuilderFactory로 원하는 Job을 쉽게 만들 수 있다.
public class JobBuilderFactory {
private JobRepostiroy jobrepository;
public JobBuilderFactory(JobRepository jobRepository){
this.jobrepository = jobrepository;
}
public JobBuilder get(String name){
JobBuilder builder = new JobBuilder(name).repository(jobrepository);
return builder;
}
}
휴면회원 배치 구현
배치처리 순서는 다음과 같다.
- 휴면 회원 Job 설정
- 휴면 회원 Step 설정
- 휴면 회원 Reader,Processor,Writer 설정
Job 설정
@Configuration
public class InactiveUserJobConfig {
...
@Bean
public Job inactiveUserJob(JobBuilderFactory jobBuilderFactory, Step inactiveJobStep) { //(1)
return jobBuilderFactory.get("inactiveUserJob")
.preventRestart() //(2)
.start(inactiveJobStep) //(3)
.build();
}
- Job 생성은 직관이고 편리하게 도와주는 빌더 JobBuilderFactory룰 주입받는다.
- inactiveUserJob이라
Step 설정
@Bean
public Step inactiveJobStep(StepBuilderFactory stepBuilderFactory) {
return stepBuilderFactory.get("inactiveUserStep") //(1)
.<User, User> chunk(10) //(2)
.reader(inactiveUserReader()) //(3)
.processor(inactiveUserProcessor())
.writer(inactiveUserWriter())
.build();
}
- (1)stepBuilderFactory.get(“inactiveUserStep”) 로 inactiveUserStep 이라는 이름의 StepBuilder를 생성한다. 제네릭을 사용해서 chunk()의 입력과 추력 타입을 User로 설정한다.
- chunk의 인자값은 10으로 설정해서 쓰기 시에 청크 단위로 writer()메서드를 실행시킬 단위를 지정한다. 즉 커밋단위는 10개가 된다.
- step의 reader,processor,writer를 각각 설정한다.
Reader 설정
@Bean
@StepScope //(1)
public QueueItemReader<User> inactiveUserReader() {
//(2)
List<User> oldUsers =
userRepository.findByUpdatedDateBeforeAndStatusEquals(
LocalDateTime.now().minusYears(1),
UserStatus.ACTIVE);
return new QueueItemReader<>(oldUsers); //(3)
}
- 기본 빈 생성은 싱글턴이지만 @StepScope를 사용하면 해당 메서드는 Step의 주기에 따라 새로운 빈을 생성한다 즉, 각 Step을 실행마다 새로운 빈을 만들기 때문에 지연 생성이 가능하다.주의할 사항은 @StepScope는 기본 프록시 모드가 반환되는 클래스 타임을 참조하기 때문에 @StepScope를 사용하면 반드시 구현된 반환 타입을 명시해 변환해야한다.해당 예제는 QueueItemReader라고 명시했다.
- findByUpdateDateBeforeAndStatusEquals() 메서드를 통해서 휴면 회원 리스트를 가져온다.
- QueueItemReader 객체를 생성하고 불러온 휴면회원 타깃 대상을 데이터 객체에 넣어 반환한다.
public class QueueItemReader<T> implements ItemReader<T> {
private Queue<T> queue;
public QueueItemReader(List<T> data) {
this.queue = new LinkedList<>(data); //(1)
}
@Override
public T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException {
return queue.poll(); //(2)
}
}
QueueItemReader는 큐를 사용해서 저장하면 ItemReader 구현체이다.ItemReader의 기본 반환 타입은 단수형인데 그 에 따라 구현하면 User 객체 1개씩 DB에 select 요청하므로 매우 비효율적인 방식이 될 수 있다.
- QueueItemReader를 사용해서 휴면회원으로 지정될 타깃 데이터를 한번에 불러와 큐에 담아 놓는다.
- read()메서드를 사용할 때 큐의 poll() 메서드를 통해서 큐에서 데이터를 하나식 반환한다.
Processor 설정
public ItemProcessor<User, User> inactiveUserProcessor() {
return user -> user.setInactive();
}
읽어온 타깃 데이터를 휴면 회원으로 전환시키는 Processor이다.reader에서 읽은 User를 휴면상태로 전환하는 Processor 메서드를 추가하는 예이다.
Writer 설정
public ItemWriter<User> inactiveUserWriter() {
return ((List<? extends User> users) -> userRepository.saveAll(users));
}
ItemWriter는 리스트 타입을 앞서 설정한 청크 단위로 받는다.청크 단위를 10으로 설정했기 때문에
user에게 휴면회원 10개가 주어지며 saveAll()메서드를 통해서 한번에 DB에 저장한다.
배치 심화
- 다양한 ItemReader 구현 클래스
- 다양한 ItemWriter 구현 클래스
- JobParameter 사용하기
- 테스트 시에만 H2 DB를 사용하도록 설정하기
- 청크 지향 프로세싱
- 배치 인터셉터 Listener 설정하기
- 어노테이션 기반 Listener 설정하기
다양한 ItemReader 구현 클래스
기존에는 QueueItemReader 객체를 사용해서 모든 데이터를 한번에 와서 배치처지를 진행했다.
하지만 수백,수천 개 이상의 데이터를 한번에 가져와서 메모리에 올려놓게되면 좋지 않다.
이때 배치 프로젝트에서 제공하는 PagingItemReader 구현체를 사용할 수 있다.구현제는 크게
JdbcPagingItemReader,JpaPagingItemReader,HibernatePagingItemReader가 있다.
여기서는 JpaPagingItemReader로 진행한다.
@Bean(destroyMethod="") //(1)
@StepScope
public JpaPagingItemReader<User> inactiveUserJpaReader(@Value("#{jobParameters[nowDate]}") Date nowDate) {
JpaPagingItemReader<User> jpaPagingItemReader = new JpaPagingItemReader<>();
jpaPagingItemReader.setQueryString("select u from User as u where u.createdDate < :createdDate and u.status = :status"); //(2)
Map<String, Object> map = new HashMap<>();
LocalDateTime now = LocalDateTime.ofInstant(nowDate.toInstant(), ZoneId.systemDefault());
map.put("createdDate", now.minusYears(1));
map.put("status", UserStatus.ACTIVE);
jpaPagingItemReader.setParameterValues(map); //(3)
jpaPagingItemReader.setEntityManagerFactory(entityManagerFactory); //(4)
jpaPagingItemReader.setPageSize(CHUNK_SIZE); //(5)
return jpaPagingItemReader;
}
스프링에서 destroyMethod를 사용해서 삭제할 빈을 자동으로 추적한다.destriyMethod=”“를 설정하면 warning메시지를 제거할 수 있다.
JpaPagingItemReader를 사용하면 쿼리를 직접짜고 실행하는 방법밖에는 없다.
쿼리에서 사용된 updateDate,status 파라미터를 Map에 추가해서 사용할 파라미터를 설정한다.
트랜잭션을 관리해줄 entityManagerFactory를 설정한다.
한번에 읽어올 크기를 CHUNK_SIZE 만큼 할당한다.
다양한 ItemWriter 구현 클래스
ItemReader와 마찬가지로 상황에 맞는 여러 구현 클래스를 제공한다.JPA를 사용하고 있으므로 JpaItemWriter를 적용한다.
private JpaItemWriter<User> inactiveUserWriter() {
JpaItemWriter<User> jpaItemWriter = new JpaItemWriter<>();
jpaItemWriter.setEntityManagerFactory(entityManagerFactory);
return jpaItemWriter;
}
JobParameter 사용하기
JobParameter를 사용해서 Step을 실행시킬 때 동적으로 파라미터를 주입시킬 수 있다.
테스트 시에만 H2 데이터베이스를 사용하도록 설정
@RunWith(SpringRunner.class)
@SpringBootTest
@AutoConfigureTestDatabase(connection = EmbeddedDatabaseConnection.H2)
public class DemoApplication {
....
}
@AutoConfigureTestDatabase(connection = EmbeddedDatabaseConnection.H2) 어노테이션으로 간단하게 설정 가능하다.
청크 지향 프로세싱
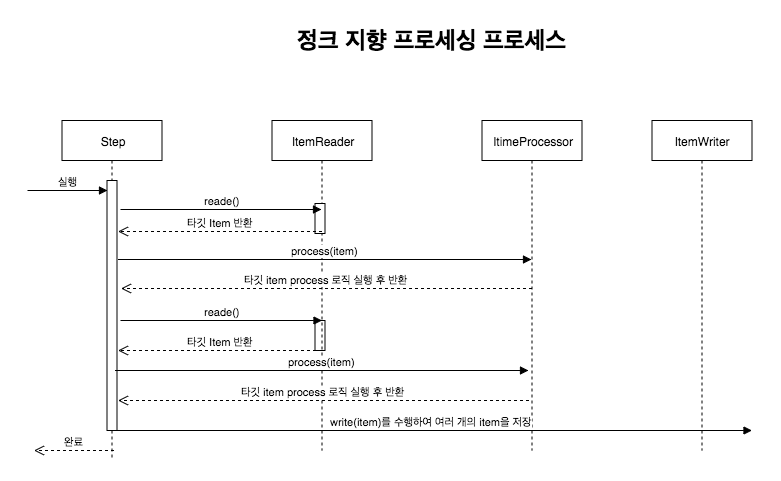
청크 지향 프로세싱은 트랜잭션 경계 내에서 청크 단위로 데이터를 읽고 생성하는 프로그래밍 기법이다.
청크랑 아이템이 트랜잭션에 커밋되는 수를 말한다.read한 데이터 수가 지정한 청크 단위와 일치하면 write를 수행하고 트랜잭션을 커밋한다.Step 설정에서 chunk()로 커밋 단위를 지정했던 부분이다.즉 기존에도 계속 사용해온 방법이 청크 지향 프로세싱이다.
청크 지향 프로그래밍의 이점은 1000개의 데이터에 대해 배치 로직을 싱행한다고 가정했을 때 청크로 나누지 않았을 때는 하나만 실패해도 다른 성곤한 999개의 데이터가 롤백된다.그런데 청크 단위를 10으로 해서 배치처리를 하면 도중에 배치 처리에 실패하더라도 다른 청크는 영향을 받지 않는다.이러한 이유로 스프링 배치에 청크 단위로 프로그래밍을 지향한다.
배치 인터셉터 Listener 설정하기
배치 흐름에서 전후 처리를 하는 Listener를 설정할 수 있다.구체적으로 Job의 전후 처리 Step의 전후 처리 각 청크 단위의 전후 처리 등 세세한 과정 실행시 특정 로직을 할당해 제어할 수 있다.가장 대표적인 예로는 로깅 작업이 있다.
어노테이션 기반 Listener 설정하기
배치 인터셉터 인터페이스를 활용해서 사용하는 방법도 있고 어노테이션을 사용해서 활용하는 방법도 있다.
대표적으로 @BeforeStep,@AfterStep 등이 있다.해당 어노테이션으로 시작 전후에 로그를 남기는 설정도 가능하다.
JobParameter 사용하기
JopParameter를 사용해서 Step을 실행시킬 때 동적으로 파라미터를 주입시킬 수 있다.
Step의 흐름을 제어하는 Flow
Step의 가장 기본적인 흐름은 읽기-처리=쓰기 이다.여기서 세부적인 조건에 따라서 Step의 실행여부를 정할 수 있다.
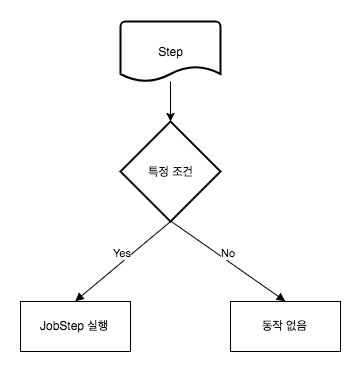
흐름에서 조건에 해당하는 부분을 JobExecutionDecider 인터페이스를 사용해 구현할 수 있다.
JobExecutionDecider 인터페이스는 decide() 메서드 하나만 제공한다.
public interface JobExecutionDecider {
FlowExecutionStatus decide(JobExecution jobExecution, @Nullable StepExecution stepExecution);
}
public Class xxxJobExecutionDecider implements JobExecutionDecider {
@Override
public FlowExecutionStatus decide(JobExecution jobExecution, @Nullable StepExecution stepExecution){
if(특정 조건...){ // (1)
return FlowExecutionsStatus.COMPLETED; // (2)
}
return FlowExecutionsStatus.FAILED; // (3)
}
}
- 특정 조건에 대한 로직
- 조건에 만족하고 JopStep을 실행 시킬 경우 COMPLETE 리턴
- 조건에 만족하지 않고 JopStep을 실행하지않을 경우 FAILED 리턴
Flow 조건으로 사용될 경우 inactiveJobExecutionDecider 클래스를 구현했다.
이를 사용할 Flow을 구현해야 한다.Step 메서드가 아닌 Flow를 주입받고 주입받은 Flow를 빈으로 등록해야한다.
Step 메서드가 아닌 Flow를 주입 받고 그 주입받은 Flow를 빈으로 등록해야 한다.
@Bean
public Flow xxxJobFlow(Step xxxJobStep){
FlowBuilder<Flow> flowBuilder = new FlowBuilder<>("xxxJobFlow"); // (1)
return flowBuilder
.start(new xxxJobExcetuinDeicder()) // (2)
.on(FlowExecutionStatus.FAILED.getName()).end() // (3)
.on(FlowExecutionStatus.COMPLETED.getName()).to(xxxJobStep).end(); // (4)
}
- FlowBuilder를 이용해서 Flow 객체를 생성한다.
- 위에서 작성한 xxxJobExecutionDecider 클래스를 start()으로 설정해 맨 처음 시작하도록 한다.
- xxxJobececutionDecider 클래스의 decide() 메서드를 통해 리턴 값이 FAILED일 경우 end() 메서드를 사용해서 끝나도록 설정한다.
- xxxJobExecutionDecider 클래스의 decide() 메서드를 통해 리턴 값이 COMPLETED일 경우 기존에 설정한 xxxJobStep을 실행하도록 설정한다.
재시도
네트워크 접속이 끊어지거나 장비가 다운되는 등 실패 시나리오는 다양하다.
스텝 구성하기
@Bean
public Step step1() {
return steps.get("user xxxxx")
.<User, User>chunk(10)
.faulTolerant()
.retryLimit(3).retry(XXXXXException.class)
.render(something())
.writer(something())
.build();
}
자바 구성으로 재시도를 활성화 할 경우,첫 번째 스텝은 오류를 허용하도록 만들어야 재시도 재한 횟수 및 재시도 대상 예외를 지정할 수 있다.먼저 fautTolerant()로 오류 허용 스텝을 얻은 후,retryLimit() 메서드로 재시도 제한 횟수,retry() 메서드로 재시도 대상 예외를 발생한다.
재시도 템플릿
- 스프링 배치가 제공하는 재시도 및 복구 서비스를 코드에 활용하는 다은 방법도 있다.재시도 로직을 구현된 커스텀 ItemWriter를 작성하거나 아예 전체 서비스 인터페이스에 재시고 기능을 입힐 수 있다.
- 스프링 배치 RetryTemplate은 바로 이런 용도로 만들어진 클래스이다.비즈니스 로직과 재시고 로직을 분리해서 마치 재시도 없이 한 번만 시도하는 것처럼 코드를 작성할 수 있게 해준다.
- 재시도->실패->복구 반복적인 과정을 간명한 하나의 API 메서드로 호출을 감싼 RetryTemplate는 여러가지 유스 케이스를 지원한다.
public class RetryableUserRegistrationServiceItemWriter implements ItemWriter<UserRegistration> {
private static final Logger logger = LoggerFactory.getLogger(RetryableUserRegistrationServiceItemWriter.class);
private final UserRegistrationService userRegistrationService;
private final RetryTemplate retryTemplate;
public RetryableUserRegistrationServiceItemWriter(UserRegistrationService userRegistrationService, RetryTemplate retryTemplate) {
this.userRegistrationService = userRegistrationService;
this.retryTemplate = retryTemplate;
}
/**
* takes aggregated input from the reader and 'writes' them using a custom implementation.
*/
public void write(List<?extends UserRegistration> items)
throws Exception {
for (final UserRegistration userRegistration : items) {
UserRegistration registeredUserRegistration = retryTemplate.execute(
(RetryCallback<UserRegistration, Exception>) context -> userRegistrationService.registerUser(userRegistration));
logger.debug("Registered: {}", registeredUserRegistration);
}
}
}
....
@Bean
public RetryTemplate retryTemplate() {
RetryTemplate retryTemplate = new RetryTemplate();
retryTemplate.setBackOffPolicy(backOffPolicy());
return retryTemplate;
}
@Bean
public ExponentialBackOffPolicy backOffPolicy() {
ExponentialBackOffPolicy backOffPolicy = new ExponentialBackOffPolicy();
backOffPolicy.setInitialInterval(1000);
backOffPolicy.setMaxInterval(10000);
backOffPolicy.setMultiplier(2);
return backOffPolicy;
}
재시도 시간 간격을 정하는 BackOffpolicy는 RetryTemplate의 유용한 기능이다.실제로 실패 직후 재시도하는 시간 간격을 늘려 여러 클라이언트가 같은 호출 할때 스텝이 잠기지 않도록 예방하는 수단으로 활용할 수 있다.
AOP 기반 재시도
스프링 배치가 제공하는 AOP 어드바이저를 이용해서 RetryTemplate 처럼 사용할 수 있다.프록시 전체에 재시 로직 어드바이스를 추가하면 RetryTemplate가 빠진 본래 코드 그대로 사용가능하다.
@Retryable(backoff = @Backoff(delay = 1000, maxDely = 10000, multiplier = 2))
public User batchSomething(){....}
Spring Batch Table
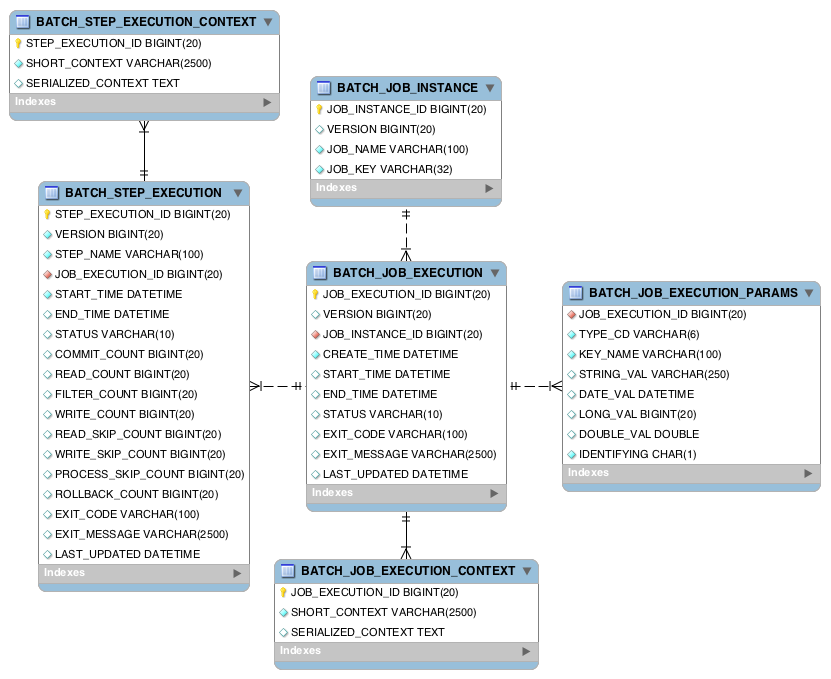
BATCH_JOB_INSTANCE
CREATE TABLE `BATCH_JOB_INSTANCE` (
`JOB_INSTANCE_ID` bigint(20) NOT NULL,
`VERSION` bigint(20) DEFAULT NULL,
`JOB_NAME` varchar(100) NOT NULL,
`JOB_KEY` varchar(32) NOT NULL,
PRIMARY KEY (`JOB_INSTANCE_ID`),
UNIQUE KEY `JOB_INST_UN` (`JOB_NAME`,`JOB_KEY`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
| JOB_INSTANCE_ID | VERSION | JOB_NAME | JOB_KEY |
| 1 | 0 | inactiveUserJob | df9e59b818ab301226e71dcf67795b07 |
| 2 | 0 | inactiveUserJob | 34c2f2838f31f237450a6c7659e36995 |
| 3 | 0 | orderDailySumJob | d41d8cd98f00b204e9800998ecf8427e |
| 4 | 0 | orderDailySumJob | d6832decf796311c39d3d934a9d7cfd5 |
| 5 | 0 | orderDailySumJob | 212470e06656926b4b339a42dc5d64c3 |
JOB_INSTANCE_ID는 VATCH_JOB_INSTANCE 테이블의 PK,JOB_NAME 수행한 Batch job Name
BATCH_JOB_INSTANCE 테이블은 Job Parameter에 따라 생성된다.Job Parameter는 Spring Batch가 실행될 때 외부에서 받을 수 있는 파라미터이다.같은 Batch Job 이라도 Job Parameter가 다르면 다른 BATCH_JOB_INSTANCE에 기록된다.
BATCH_JOB_EXECUTION_PARAMS 기반으로 JOB_KEY를 만들며 해당 값은 유니크 제약 조건이 있기 때문에 같은 BATCH_JOB_EXECUTION_PARAMS을 넘기는 경우 생성되지 않는다.
BATCH_JOB_EXECUTION
CREATE TABLE `BATCH_STEP_EXECUTION` (
`STEP_EXECUTION_ID` bigint(20) NOT NULL,
`VERSION` bigint(20) NOT NULL,
`STEP_NAME` varchar(100) NOT NULL,
`JOB_EXECUTION_ID` bigint(20) NOT NULL,
`START_TIME` datetime NOT NULL,
`END_TIME` datetime DEFAULT NULL,
`STATUS` varchar(10) DEFAULT NULL,
`COMMIT_COUNT` bigint(20) DEFAULT NULL,
`READ_COUNT` bigint(20) DEFAULT NULL,
`FILTER_COUNT` bigint(20) DEFAULT NULL,
`WRITE_COUNT` bigint(20) DEFAULT NULL,
`READ_SKIP_COUNT` bigint(20) DEFAULT NULL,
`WRITE_SKIP_COUNT` bigint(20) DEFAULT NULL,
`PROCESS_SKIP_COUNT` bigint(20) DEFAULT NULL,
`ROLLBACK_COUNT` bigint(20) DEFAULT NULL,
`EXIT_CODE` varchar(2500) DEFAULT NULL,
`EXIT_MESSAGE` varchar(2500) DEFAULT NULL,
`LAST_UPDATED` datetime DEFAULT NULL,
PRIMARY KEY (`STEP_EXECUTION_ID`),
KEY `JOB_EXEC_STEP_FK` (`JOB_EXECUTION_ID`),
CONSTRAINT `JOB_EXEC_STEP_FK` FOREIGN KEY (`JOB_EXECUTION_ID`) REFERENCES `BATCH_JOB_EXECUTION` (`JOB_EXECUTION_ID`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
| JOB_EXECUTION_ID | VERSION | JOB_INSTANCE_ID | CREATE_TIME | START_TIME | END_TIME | STATUS | EXIT_CODE | EXIT_MESSAGE | LAST_UPDATED | JOB_CONFIGURATION_LOCATION |
| 1 | 2 | 1 | 2019-07-02 06:51:22 | 2019-07-02 06:51:22 | 2019-07-02 06:51:23 | COMPLETED | COMPLETED | 2019-07-02 06:51:23 | NULL | |
| 2 | 2 | 2 | 2019-07-02 07:14:00 | 2019-07-02 07:14:00 | 2019-07-02 07:14:01 | COMPLETED | COMPLETED | 2019-07-02 07:14:01 | NULL | |
| 3 | 2 | 3 | 2020-01-13 11:00:50 | 2020-01-13 11:00:50 | 2020-01-13 11:00:50 | COMPLETED | COMPLETED | 2020-01-13 11:00:50 | NULL | |
| 4 | 2 | 4 | 2020-01-13 11:59:15 | 2020-01-13 11:59:15 | 2020-01-13 11:59:15 | COMPLETED | COMPLETED | 2020-01-13 11:59:15 | NULL | |
| 5 | 2 | 5 | 2020-01-13 12:48:53 | 2020-01-13 12:48:53 | 2020-01-13 12:48:54 | COMPLETED | COMPLETED | 2020-01-13 12:48:54 | NULL |
JOB_EXECUTION_ID 칼럼은 BATCH_JOB_INSTANCE 테이블의 PK를 참조하고 있다.
BATCH_STEP_EXECUTION 와 BATCH_JOB_INSTANCE는 부모자식 관계이다.
BATCH_STEP_EXECUTION은 자신의 부모 BATCH_JOB_INSTANCE 성공/실패 내역 모두 갖고 있다.
jobParameters:Job 실행에 필요한 매개변수 데이터이다.
jobInstance:Job 실행 단위가 되는 객체이다.
stepExecutions:StepExecution을 여러 개 가질 수 있는 Collection타입이다.
status:Job 실행 상태를 나타내는 필드(Enum)이다.상태값으로는 COMPLETED,STARTING,STARTED.STOPPING,STOPPED,FAILED,ABANNDONED,UNKNOWN 이 있다.
startTime:Job이 실행된 시간이다.null이면 시작되지 않았다는 의미이다.
createTime:JobExecution이 생성된 시간이다.
endTime:JobExecution이 끝난 시간이다.

Job:특정 잡,2달 이상 로그인 안한 유저 휴면 회원 처리 등
Job Instance:Job Parameter를 실행한 Job(Job Parameter 단위로 생성)
Job Execution:Job Parameter로 실행한 Job의 실행,1번째 시도 혹은 그 다음 등
BATCH_JOB_EXECUTION_PARAMS
| JOB_EXECUTION_ID | TYPE_CD | KEY_NAME | STRING_VAL | DATE_VAL | LONG_VAL | DOUBLE_VAL | IDENTIFYING |
| 5 | STRING | requestDate | 2019-10-13 | 1970-01-01 00:00:00 | 0 | 0 | N |
| 5 | LONG | run.id | 1970-01-01 00:00:00 | 2 | 0 | Y | |
| 5 | STRING | version | 12 | 1970-01-01 00:00:00 | 0 | 0 | Y |
| 5 | STRING | -job.name | orderDailySumJob | 1970-01-01 00:00:00 | 0 | 0 | N |
BATCH_JOB_EXECUTION에 대한 Parameter정보들이 저장되는 곳이다 BATCH_JOB_EXECUTION, BATCH_JOB_EXECUTION_PARAMS 1:N 관계이며 위 테이블은 ID 5번에 들어가는 parameter 정보들이 저장된다