- 자바 언어 기초(com.eomcs.lang)
- ex03 예제
- 정수/부동소수점/문자를 2진수로 표현하는 방법
- 학습 목표 달성 확인 목록
- [] 정수를 2진수로 표현할 때 Sign-Magnitude, 1의 보수, 2의 보수, Excess-K 각각의 방식으로 표현할 수 있는가?
Sign-Magnitude(부호-크기 방식)
부동 소수점에서 가수부를 저장할때 사용한다.
맨 왼쪽 1비트는 부호 비트로 쓰인다.(0이면 +,1이면 -)
나머지 비트는 절대값으로 저장한다.
8비트 = 1비트(부호) + 7비트(절대값)
// 예) +24 => |+24| = 24 ---> 0001 1000
// 예) -24 => |-24| = 24 ---> 1001 1000
//- 수의 범위(8비트 기준): -127 ~ + 127
// 0111 1111 (127)
// 0111 1110 (126)
// 0111 1101 (125)
// ...
// 0000 0001 (1)
// 0000 0000 (+0)
// 1000 0000 (-0)
// 1000 0001 (-1)
// ...
// 1111 1101 (-125)
// 1111 1110 (-126)
// 1111 1111 (-127)
단점
-두 개의 0(-0,+0)이 존재한다.
-양수와 음수를 더했을 때 옳지 않은 값이 나온다.
예)4비트 경우 1+(-1) = ?
0001 = 1
1001 = -1
1010 = -2
-폐기를 처리하는 컴퓨팅 회로를 별도로 설계해야 하므로 하드웨어가 복잡해진다.
장점
이해하기 쉽다.
1의 보수
모든 비트를 반대 값으로 바꾼다.
+24
0001 1000
-24
1110 0111
수의 범위(8비트 기준): -127 ~ +127
// 0111 1111 (127)
// 0111 1110 (126)
// 0111 1101 (125)
// ...
// 0000 0001 (1)
// 0000 0000 (+0)
// 1111 1111 (-0)
// 1111 1110 (-1)
// ...
// 1000 0010 (-125)
// 1000 0001 (-126)
// 1000 0000 (-127)
단점
-두 개의 0(+0,-0)이 존재한다.
-두 수를 더한 후 비트 크기를 초과한 1 값을 다시 맨 뒤에 더해야만 옳은 값이 된다.
예) 4비트일 경우,
0001(+1)
1110(-1)
——–
1111(-0) <— 음수 0과 양수 0을 다뤄야 하는 것이 번거롭다.
0101(+5)
1100(-3)
——–
1 0001(1) <— 옳지 않은 값.
-
1 <— 4비트를 초과하는 값을 다시 맨 뒤에 더함.
0010(2) <— 옳은 값!
2의 보수
-자바에서 음수를 저장하는 방법이다.
-1의 보수에 문제점을 해결하기 위해 등장한 방법이다.
-음수 0을 없앰으로써 -128까지 표현 가능하다.
수의 범위(8비트 기준): -128 ~ +127
// 0111 1111 (127)
// 0111 1110 (126)
// 0111 1101 (125)
// ...
// 0000 0010 (2)
// 0000 0001 (1)
// 0000 0000 (+0)
// 1111 1111 (-1)
// 1111 1110 (-2)
// ...
// 1000 0011 (-125)
// 1000 0010 (-126)
// 1000 0001 (-127)
// 1000 0000 (-128)
-2의 보수를 만드는 방법 1:
모든 비트를 반대 값으로 만든 다음 1을 더한다.
예) 0010 1001(+41)
1101 0110(1의 보수)
1
———
1101 0111(-41)
-2의 보수를 만드는 방법 2:
오른쪽에서부터 1을 찾는다.
찾은 1의 왼쪽편에 있는 모든 비트를 반대 값으로 바꾼다.
예) 0010 1001(41) => 1101 0111(-41)
^ ^
예) 0010 1100(44) => 1101 0100(-44)
^ ^
-2의 보수를 만드는 방법 3:
- 2^n(8비트일 경우 2^8 = 256)에서 음수 값 만큼 뺀다.
예) -41 => 256 - 41 = 215 = 1101 0111
예) -44 => 256 - 44 = 212 = 1101 0100
K-초과(Excess-K)
부동 소수점의 지수부(exponent)를 저장할 때 사용한다.
오프셋 바이너리(offset binary) 또는 바이어스된 표기법(biased representation) 이라고도 한다.
K를 바이어스 값이라 부르며, 표현하려는 값에 더할 때 사용한다.
표현하려는 값 + 초과 값(K) = 결과
바이어스 값(K)을 구하는 공식:
K = 2^(비트수 - 1)
예) 8비트일 경우 —> K = 2^(8 - 1) = 2^7 = 128, 결과 = 128 + 값
1111 1111 = 128 + 127 <-0까지 포함하여 128개가 된다.
1111 1110 = 128 + 126
1111 1101 = 128 + 125
…
1000 0001 = 128 + 1
1000 0000 = 128 + 0 <-기준이 된다
0111 1111 = 128 + (-1)
…
0000 0010 = 128 + (-126)
0000 0001 = 128 + (-127)
0000 0000 = 128 + (-128)
- [] 정수를 저장할 때 Sign-Magnitude 가 아닌 2의 보수 방식으로 저장하는 이유를 아는가?
연산도 가능하고 숫자를 표현하는데 범위의 손실이 없어서 Sign-Magnitude 방법보다 휠씬 좋아서 컴퓨터에서는 2의 보수법을 사용한다.
- [] 값을 2진수로 표현하는 이유는 무엇인가?
컴퓨터는 0과1만 인식할수 있다.즉 1비트에는 1또는 0이 들어갈수 있다는 뜻이며
즉 데이터로 저장할 수 있다.
- [] 정수 말고, 2진수로 표현하는 다른 종류의 값을 말할 수 있는가?
부동소수점
- [] 부동소수점을 리터럴로 표현할 수 있는가?
예를들어 10진수인 3.14를 e 기호로 사용하여 부동소수점을 나타내겠다.
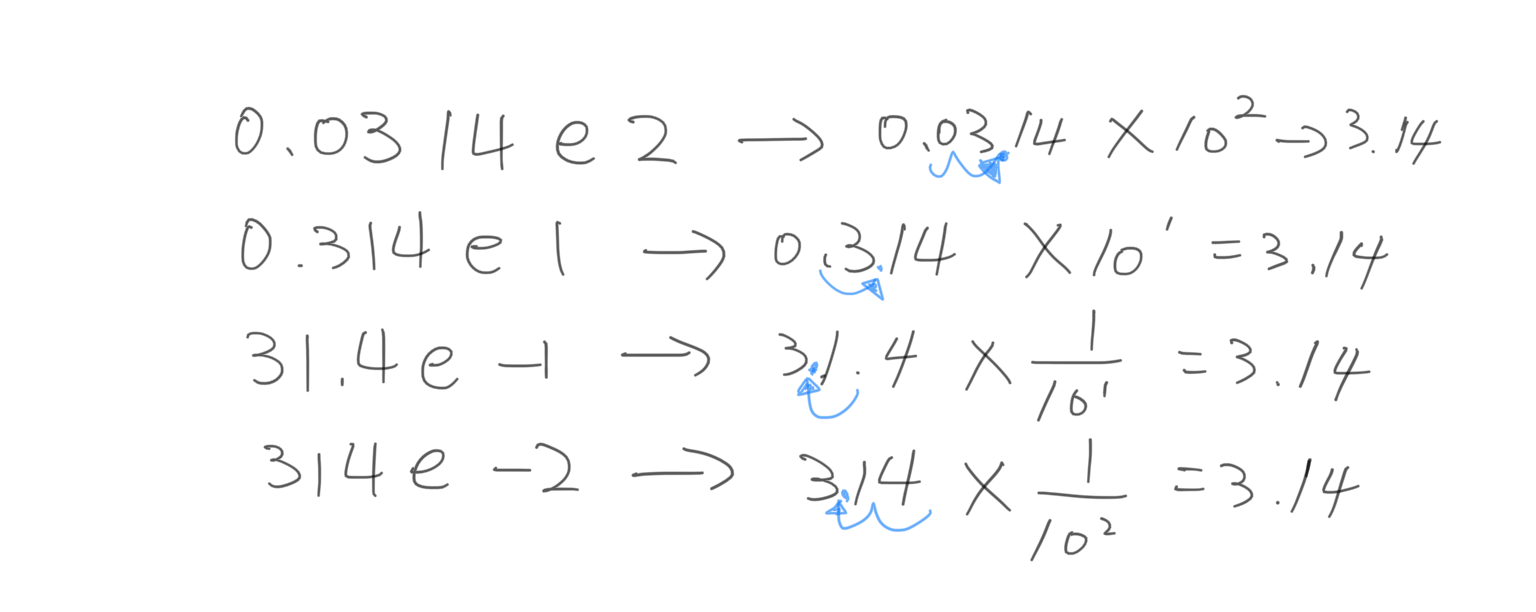
8바이트의 부동소수점
3,14 || 3.14d||D
아무것도 없거나 대소문자d를 숫자뒤에 입력하면 된다.
4바이트의 부동소수점
3.14f || 3.14F
숫자 맨뒤에 대소문자f를 입력하면 된다.
- [] 부동소수점을 메모리 크기에 따라 4바이트, 8바이트 리터럴로 구분하여 표현할 수 있는가?
정확하게 소수점 이상 얼마까지 소수점 이하 얼마까지 식으로 정의할 수 없지만
대신 유효자릿수라는 방식으로 대략 값의 범위를 표현 할 수있다.
//## 4byte(float) 부동소수점의 유효자릿수
//소수점을 뺀 후 7자리 숫자까지는 거의 정상적으로 저장된다.
System.out.println(999.9999f);
System.out.println(999999.9f);
System.out.println(9.999999f);
System.out.println("----------------------------");
//유효자릿수가 7자리를 넘어가는 경우 값이 잘려서 저장될 수 있다.
System.out.println(987654321.1234567f);//987654340.0 메모리 저장값
System.out.println(9.876543211234567f);
System.out.println(987654321123456.7f);
System.out.println("----------------------------");
//## 8byte(double) 부동소수점의 유효자릿수
//소수점을 뺀 후 16자리 숫자까지는 거의 정상적으로 저장된다.
System.out.println(987654321.1234567);
System.out.println(9.876543211234567);
System.out.println(987654321123456.7);
System.out.println("----------------------------");
//유효자릿수가 16자리를 넘어가는 경우 값이 잘려서 저장될 수 있다.
System.out.println(987654321.12345678);
System.out.println(9.8765432112345678);
System.out.println(987654321123456.78);
System.out.println("----------------------------");
//## 부동소수점을 저장할 때 정확하게 저장되지 않는 예
System.out.println(7 * 0.1); //결과: 0.7000000000000001
//- 이유
// - IEEE-754 규격에 따라 부동소수점을 2진수로 바꾸다보면
// 정확하게 2진수로 딱 떨어지지 않는 경우가 있다.
// CPU, OS, 컴파일러, JVM의 문제가 아니다.
// - IEEE-754의 방법에 내재되어 있는 문제다.
//- 해결책
// - 시스템에서 필요한 만큼 소수점 이하 자리수를 적절히 짤라 사용하라!
- [] 부동소수점을 2진수로 표현할 수 있는가?
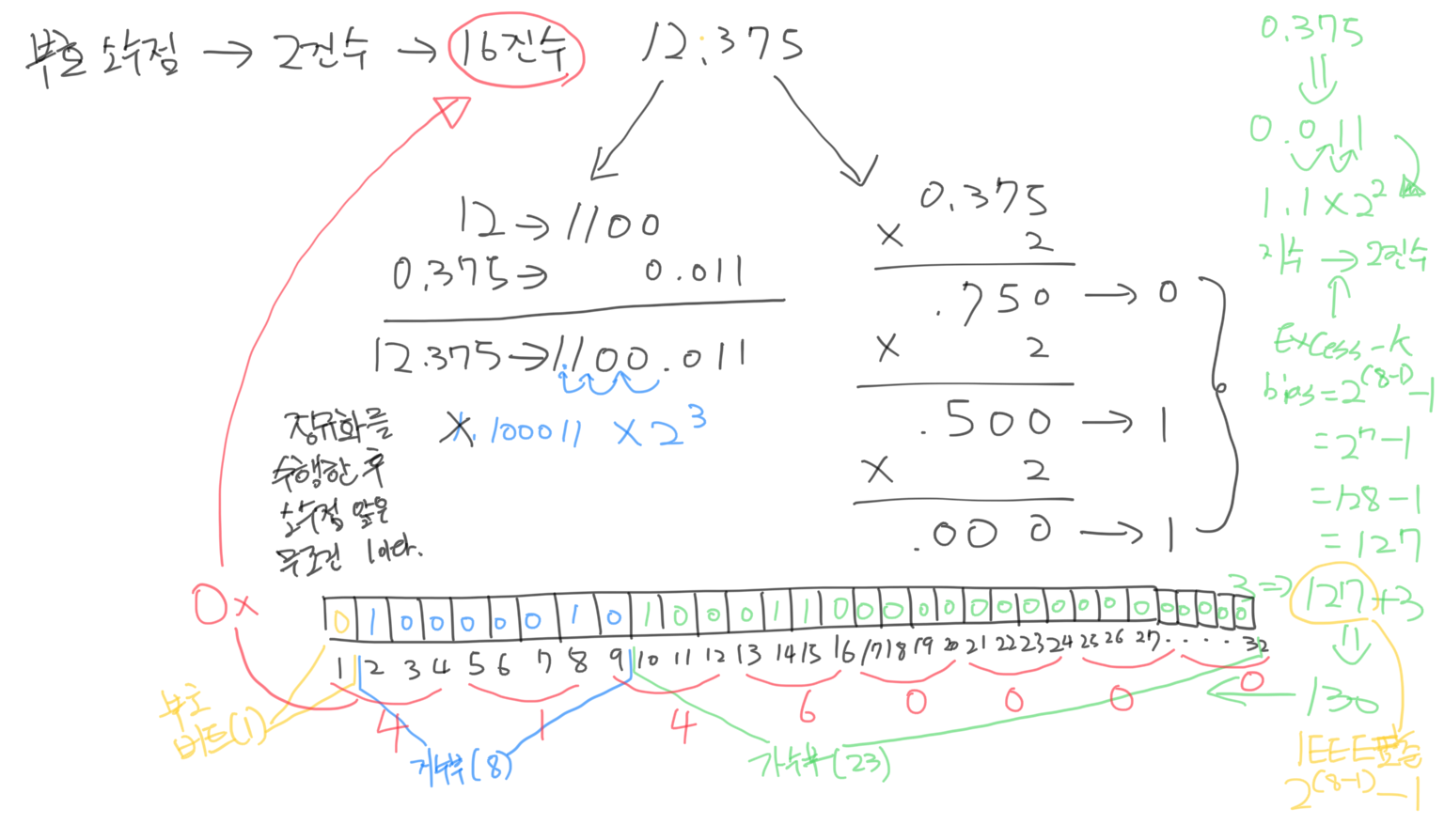
- [] 부동소수점의 범위를 유효자릿수로 표현하는 이유를 아는가?
정확하게 소수점 이상 얼마까지 소수점 이하 얼마까지 라는 정의를 할수가 없다
그래서 유효자릿수라는 방식을 사용하여 대략적이라는 값의 범위를 알수 있다.
- [] 4바이트 부동소수점과 8바이트 부동소수점의 유효자릿수는 무엇인가?
4바이트는 소수점을 뺀 나머지 7자리
8바이트는 소수점을 뺀 나머지 16자리
- [] 문자의 2진수 표현을 정의한 것을 무엇이라 부르는가?
문자집합 character set이라고 부른다.
- [] character set의 다양한 종류(ASCII,ISO-8859-1,EUC-KR,조합형,MS949,Unicode,UTF-8,UTF16)와 그 특징을 설명할 수 있는가?
ASCII:기본적인 문자 집합으로 128개의 문자로 7비트이며 영어알파벳인 로마자의 기본 26자의 대소문자와 숫자,특수문자들을 포함한다.
ISO-8859-1:기존 ASCII을 그대로 유지했으며 8비트로 확장하여 서유럽에서 필요로 하는 문자와 몇가지 특수 문자를 추가했다.
EUC-KR:8비트를 사용하는 문자 인코딩이며 대표적인 한글 완성형 인코딩이기 때문에 보통 완성형이라고 부른다.
조합형:글자 하나를 만들때 초성+중성+종성을 조합하여 만든다.자모의 특정한 값을 가지고 이러한 값들의 나열로부터 글자를 조합하기에 이름이 그렇다.
MS949:ms사가 기존 한글 2350자밖에 지원하지 않던 ks x 1001이라는 한글산업표준문자세트를 확장해 만든것이다.
Unicode:전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준이다.
UTF-8:유니코드를 위한 가변 길이 문자 인코딩 방식 중 하나로 유니코드 한 문자를 나타내기 위해 1바이트에서 4바이트까지 사용한다.
UTF16:유니코드 문자 인코딩 방식중 하나이며 주로 사용되는 기본 다국어 평면에 속하는 문자들을 그대로 12비트 값으로 인코딩이 되고
그 이상의 문자는 특별히 정해진 방식으로 32비트로 인코딩이 된다.
- [] 자바에서는 UTF-16BE(UCS2)을 기본 character set으로 사용한다는 것을 아는가?
자바에서는 문자 하나를 저장하면 바이트 수는 영문자이든 한글문자이든 2바이트를 차지하게 된다.