create table tab_OID(id integer); --테이블생성
-- 위에서 생성한 테이블의 oid 조회
select OID, relname from pg_class where relname ='tab_oid'; --16426,tab_oid
select 'tab_oid'::regclass::oid; --16426
생성한 테이블의 OID 조회 가능
main fork에 대해서
데이터를 저장하는 파일의 용량이 1GB를 넘기게 되면 DB는 해당 파일을 세그먼트로 나눠서 관리하게 된다 이때 relfilenode이라고 명칭한다.
예들을어 oid=111인 객체 즉 테이블(relfilenode=16000으로 테이블 생성시 선언되는 값)이 1GB를 넘기게 되면 새로운 파일의 relfilenode은 16000.1, 16000.2, 16000.3 … 이라고 세그먼트 파일이 생성된다. 만약 VACUUM FULL이 동작해서 delete된 파일들을 정리해서 새로운 relfilenode이 생기면 17000로 생성하여 해당 파일에 남은 데이터들을 이동한다.
위의 내용을 정리한 표이다.
| 구분 | 상세 내용 |
| 기본 파일명 | 테이블 생성 시 pg_class의 relfilenode 값을 이름으로 가짐 (예: 16000) |
| 세그먼트 분할 | 파일이 1GB에 도달하면 16000.1, 16000.2 식으로 확장됨 |
| 일반 VACUUM | 기존 파일(16000) 내부의 쓰레기만 치움. 파일명 유지. |
| VACUUM FULL | 새 파일(17000)을 만들어 유효 데이터만 이사 시킴. 파일명 변경. |
| 연결 고리 | 파일명이 바뀌면 pg_class 장부의 relfilenode 컬럼 값도 새 번호로 갱신됨 |
free space map(fsm)
데이터가 변경되면 빈공간이 생기게 된다. 그이후에 추가되는 값은 어느 relfilenode에 저장할지 판단해야된다.
이때 fsm을 확인해서 해당 테이블의 relfilenode의 어느 페이지(page)로 갈지 판단한다.
relfilenode를 조회했을때 16000이면 fsm 파일명은 16000_fsm으로 생성된다.
만약 새로 생성한 테이블이면 oid값과 relfilenode값은 서로 같을수 있다.
위의 내용을 정리한 표이다.
| 구분 | 상세 내용 |
| 데이터 변경(Update/Delete) | 기존 자리에 구멍(빈 공간)이 생김 |
| FSM 업데이트 | VACUUM이나 일반적인 작업 중에 “이 페이지에 자리가 났다”고 _fsm 파일에 기록함 |
| 새 데이터 입력(Insert) | _fsm 지도를 보고 빈 구석을 찾아 들어가서 공간을 알뜰하게 재활용함 |
| 연결 | relfilenode(실제 파일) + _fsm(빈자리 지도) + _vm(청소 지도)은 항상 세트로 움직임 |
fsm 확인방법
CREATE EXTENSION pg_freespacemap;
create table t1
(
id integer,
name char(2000)
);
alter table t1 set(autovacuum_enabled=false);
insert into t1
select i as id, 'aaa' as name
from generate_series(1, 20) a(i);
select * from pg_freespace('t1');
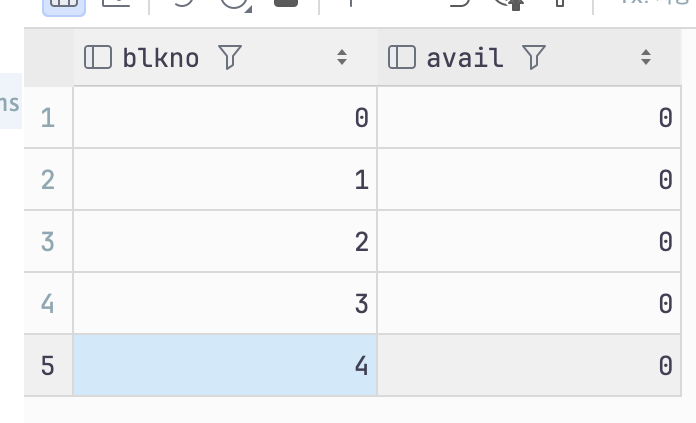
update t1 set name='bbb';
select * from pg_freespace('t1');
데이터 업데이트를 하면 데드 튜플이 증가되어 페이지 갯수는 2배로 증가함을 확인 가능
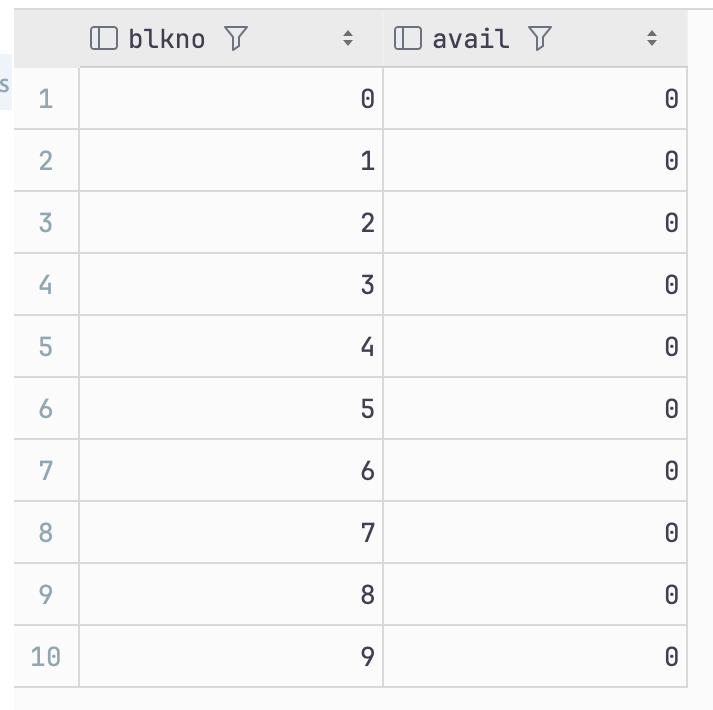
vaccum을 동작시켜서 dead tuple을 정리
vacuum t1;
select *, round(100 * avail / 8192, 2) as freespace_ratio
from pg_freespace('t1');
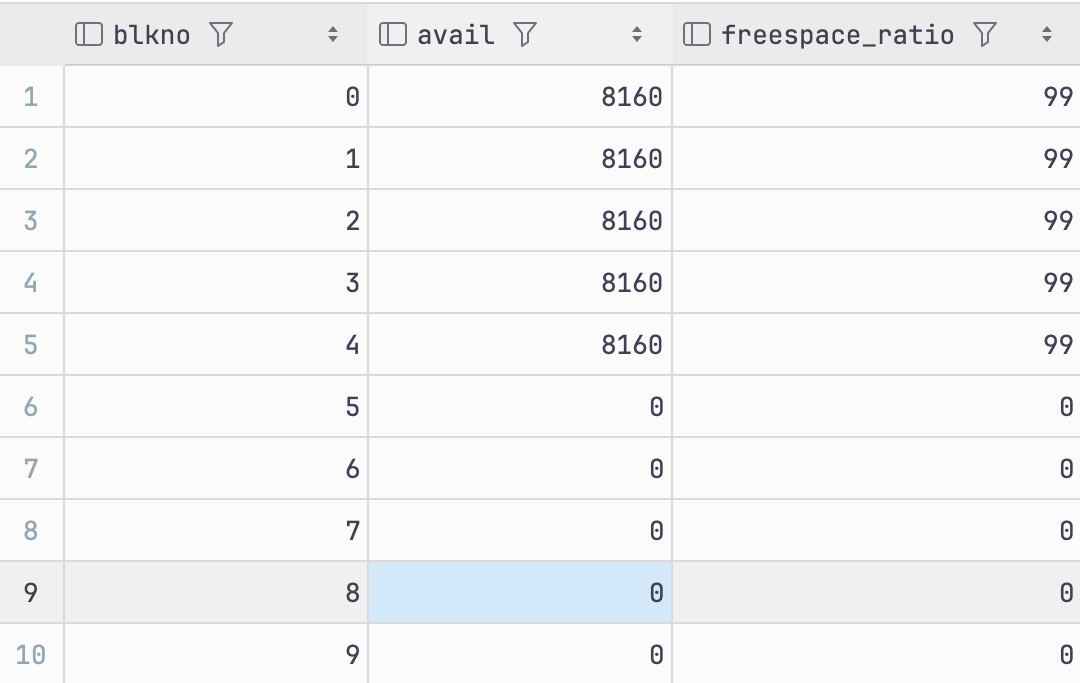
업데이트된 tuple은 유지되고 dead 처리된 tuple들은 비활성화되어서 freespace가 초기화됨을 확인
VM(Visibility Map)
- VM(Visibility Map)은 테이블의 페이지 단위로 해당 페이지의 모든 tuple이 visible한지(all-visible) 를 관리한다.
- Vacuum은 VM을 참고하여 이미 all-visible인 페이지는 스캔을 건너뛰어 성능을 높인다.
- 즉 all-visible하지 않은 페이지라면 vaccum에게 해당 페이지 확인해서 vaccum처리하라고 알려주는 파일이다.
- 또한 VM의 all-visible 정보 덕분에 Index Only Scan이 가능하며, 이 경우 heap(실제 테이블)을 직접 조회하지 않아도 된다.
SHOW data_directory; --/var/lib/postgresql/data
select pg_relation_filepath('테이블명'); --base/5/16412
해당 path들을 검색해서 postgresql에서 관리하는 fork 영역을 관리하는 파일들을 직접 확인 가능하다.
select 쿼리 동작
- 먼저 해당 테이터 index에서 id를 조회하여 어느 페이지에 저장되었는지 찾는다.
- 해당 페이지의 vm을 확인해서 all-visible하면 index에 저장된 값을 바로 반환한다.(비용절감됨)
- 만약 all-visible하지 않은 데이터라면 실제 데이터가 저장된 디스크에서 읽어서 값을 반환한다.
all-visible과 all-frozen
all-visible은 해당 페이지는 인덱스에 저장된 값을 바로 반환해도 된다는 의미
vaccum에게도 skip해도된다는 의미지만 낮은 확률로 vaccum 동작할수 있음
all-frozen은 해당 페이지는 절대 값이 변하지 않는다는 의미
비트값이 1 즉 true면 해당 페이지는 vaccum이 아예 동작하지 않아도 된다는 의미
all-visible/all-frozen
테이블 생성되고 데이터가 입력되면 vm의 값은 0,0 조합
vaccum이 동작되면 vm의 값은 1,0 또는 1,1 상태가 된다.(vaccum이 동작했기때문에 all-visible=true가 된다.)
vaccum freeze 옵션으로 동작시키면 무조건 1,1이 된다.
delete,update 쿼리가 수행하면 항상 0,0이 된다.
vm 정보 확인 테스트
drop table t1; -- 기존 테이블 삭제
create table t1
(
id integer,
name char(2000)
); -- 테이블 생성
insert into t1
select i as id, 'aaa' as name
from generate_series(1, 10) a(i); -- 데이터 입력
select blkno, all_visible, all_frozen
from pg_visibility('t1');
빈 페이지에 insert가 발생하면 all-visible,all-frozen은 0 즉 false로 반환된다.
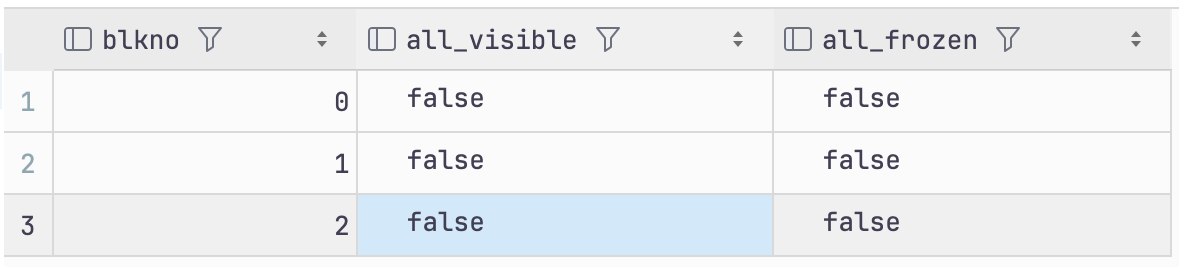
빈 페이지에 데이터가 저장되면 모든 값은 false
vacuum t1; -- vaccum 동작
select blkno, all_visible, all_frozen
from pg_visibility('t1'); -- 조회
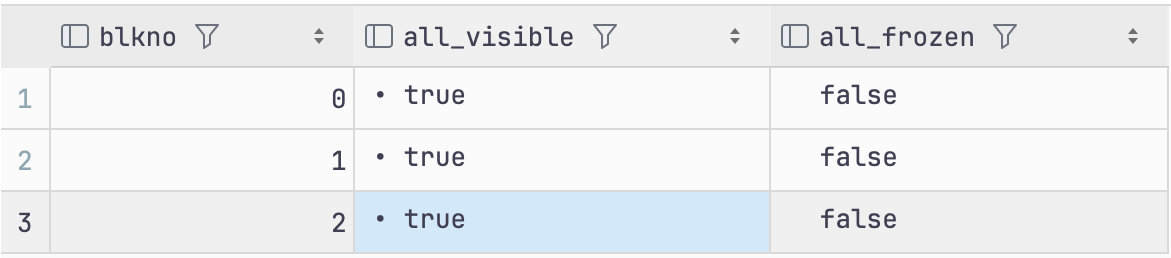
vaccum을 동작시키면 all-visible은 true
update t1
set name = 'ccc'
where id = 1; -- update로 인해 dead tuple 발생
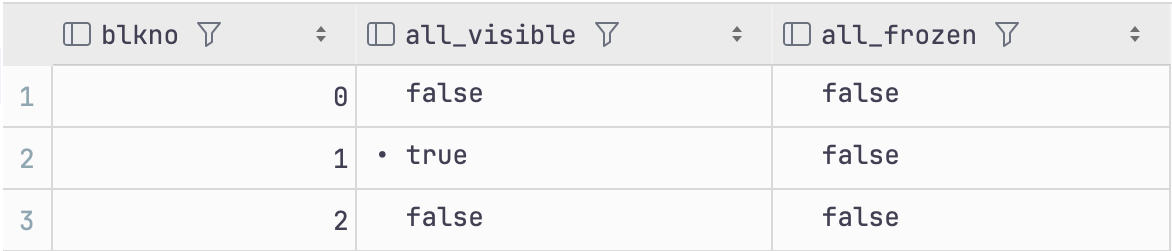
dead tuple이 발생하여 all-visible이 false
잠깐! 왜 where절로 한개의 로우만 업데이트 했는데 두개의 페이지가 all-visible=false처리되었냐면 update쿼리는 변경된 값을 insert 처리하기 때문에 dead tuple이 발생한 페이지와 업데이트되어 insert된 페이지 총 2개의 페이지가 all-visible=false처리가 된다.
vacuum freeze t1; --vaccum freeze 수행
select blkno, all_visible, all_frozen
from pg_visibility('t1'); -- 확인

모든 페이지의 all-visible과 all-freeze가 true
이렇게 되면 ‘현재 노출할 수 있는 데이터는 최신화 데이터라서 더이상 확인할 필요가 없다’ 라는 의미가 된다.